
Pervasive Artificial Intelligence Research (PAIR) Labs
Video Compression based on Generative Model
Principal Investigator:Professor Wen-Hsiao Peng
—
Summary
The deep learning schemes recently developed provide a new direction for constructing a high-efficiency compression image/video coding system. Our research focuses on the essential elements of a video compression system including image compression, video frame predictor, compression residual artifacts reduction, saliency map estimation, and compression-oriented multi-task training. These topics are either the backbone of an image/video compression system or they can enhance the compression efficiency.
Keywords
Image Compression, Video Compression, Depth Learning, Video Predictor, Saliency Detection, Auto-encoder (AE), Generative Adversarial Network (GAN).
Innovations
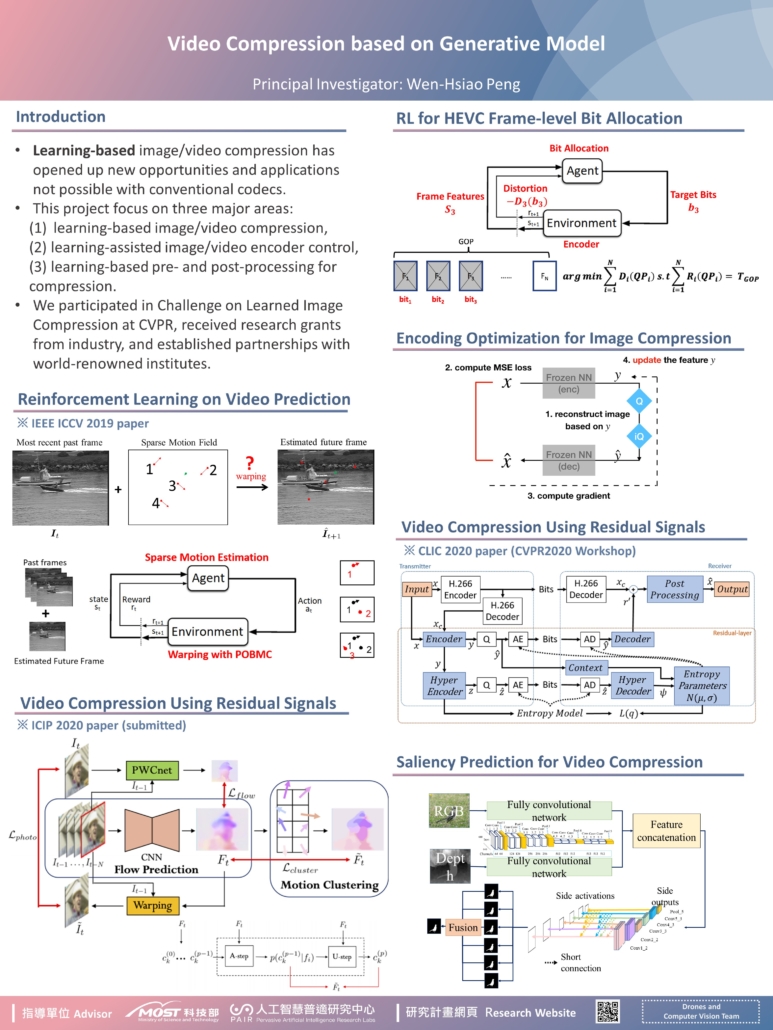
- One key issue in the image compression system design is that the Latent Variables (in an autoencoder) need to have low entropy rate and can be easily coded using a small number of bits. We use the autoencoder (AE) and the recurrent neural network (RNN) models to design the end-to-end image compression systems. AE is able to perform representation learning and dimensionality reduction from an input image. And RNN can easily support multi-bitrate image reconstruction after the end-to-end training.
- We train a neural network to determine the number of target bits for each frame in a GOP based on observing the intra- and inter-frame texture complexity and the bit budget. Both state signals are updated on the fly as the encoding moves along.
- We design a multitask network to extract a unified semantic representation that can compress image/video and analyze the content of video at the same time. Ideally, this network will learn to generate meaningful compressed features.
- We develop a modified network based on the FCN model with short connections to retrieve different levels of features to predict salient objects. A more efficient model with a modified design of loss function is used in our training network without the need of a post-processing module.
Benefits
- In the AE structure, we include multi-bit quantizer together with importance map and context model to improve the compression efficiency and multi-rate compression functionality. Some initial results are shown in Fig.1. To improve the coding performance in the RNN structure, we replace the encoder and decoder layer by the Gated Recurrent Unit (GRU) and include the multi-scale mechanism inside the system.
- We propose an RL-based frame-level bit allocation scheme for HEVC/H.265. We address it as an RL problem and implement the scheme on x265-2.7. Compared with the x265-2.7 algorithm, our proposed model is able to achieve better control of GOP-level bit rates. Some initial results are shown in Table 1.
- The multitask network can provide the following three advantages (Fig2):
- The proposed network composed of many convolutional layers, pooling layers, and Resnet blocks can learn more semantic features for image reconstruction and segmentation.
- By generating the importance map and adjusting the size of the quantized code, we can control the bit rate for the image compression.
- By learning the weighted parameter defined in the cross-stitch module, we can explore the relationship between the reconstruction task and the segmentation task. Specifically, we may know a better way to share the features between the two streams.
- We have proposed an RGBD salient object detection model based on the FCN network with short connection (Fig.3). A deep learning network with the capacity of making the detection results more coherent spatially is developed in this work. A new loss function is proposed to enhance spatial coherence.

{kind=link}